
Thomas Kahn, Ph.D.
Biophysicist turned Data Scientist
About Me
I've dedicated the majority of my adult life to studying the molecular machinery of biology. This pursuit recently culminated with the completion of a doctorate in Biochemistry and Molecular Biophysics from Columbia University, during which I investigated protein folding and misfolding through the direct isolation and manipulation of single protein molecules with mechanical force. The progress of my research critically depended on the development and proper application of quantitative analytical tools in order to overcome the severe amount of noise and stochasticity associated with nanoscale systems. In developing technical skills along these lines, I became strongly interested in machine learning and data visualization techniques in a general sense, and the powerful effects that they manifest when skillfully applied. I am now seeking opportunities to continue expanding my abilities through immersive, practical application of my broad quantitative and scientific training to the solving of problems in a modern, data-driven business environment.
Portfolio
Optimization of Support Vector Machine Classification
In this report, I describe support vector machine classification and demonstrate a robust method to optimize parameter values and obtain the most accurate models while avoiding overfitting.
Project Euler Solutions

In this GitHub repository, I provide solutions to (and discuss the mathematical background of) several problems from Project Euler, a collection of recreational mathematics problems that most often require creative computational approaches to solve. My solutions are composed in Python, C++, Julia, and MATLAB, and therefore illustrate how idiomatic features of the individual languages can be leveraged for various numerical computation tasks.
Visualizing US Economic Trends Over the Past Four Decades
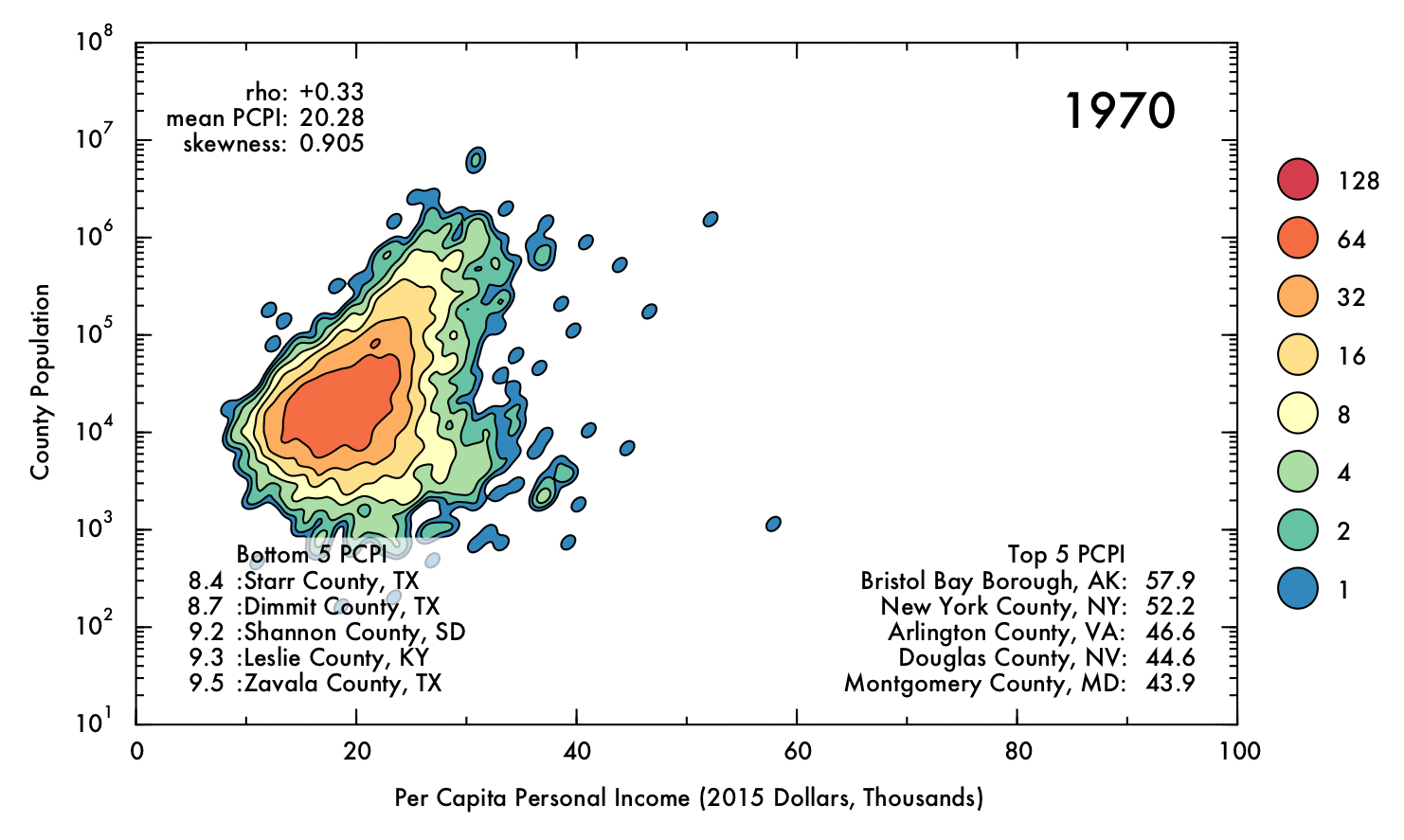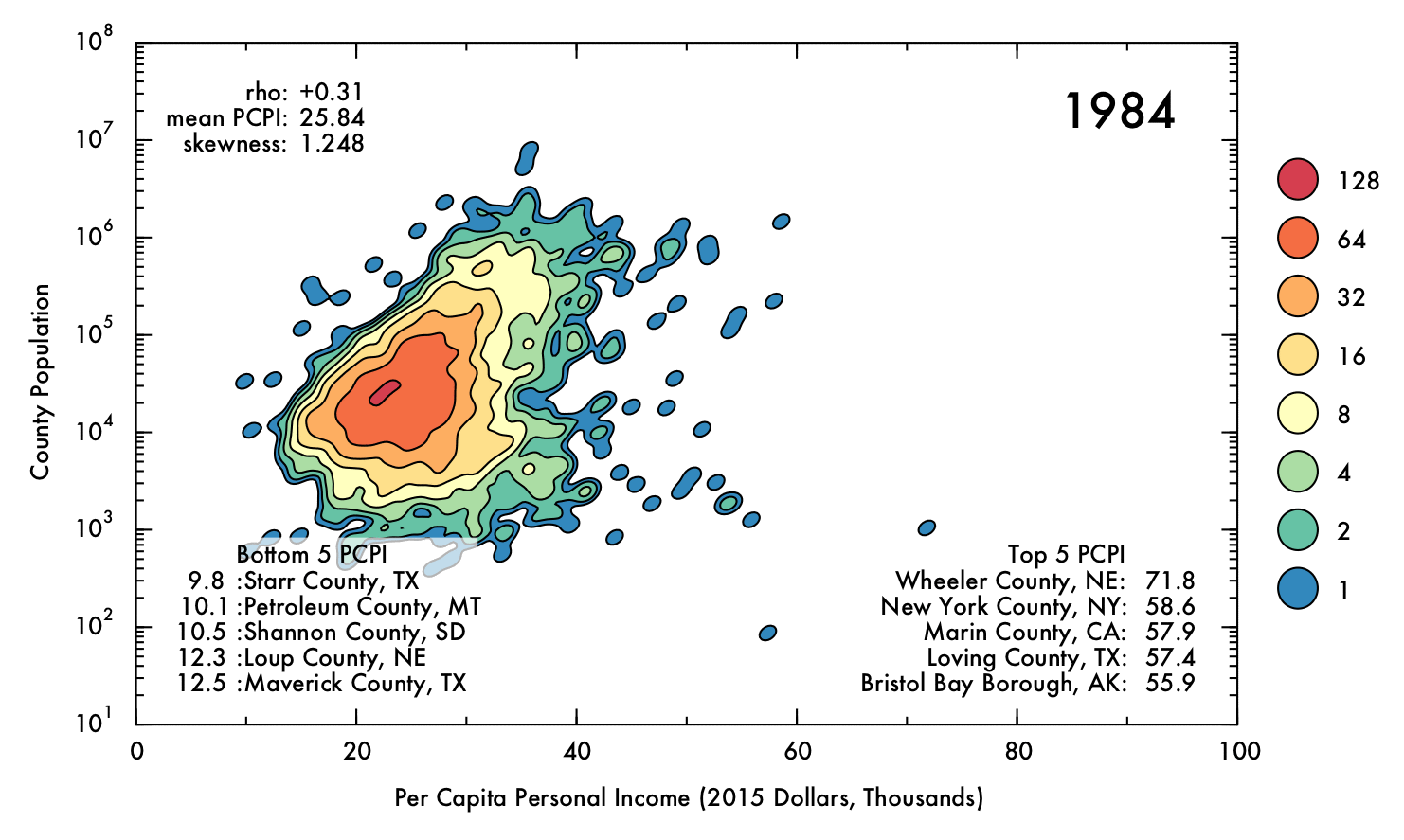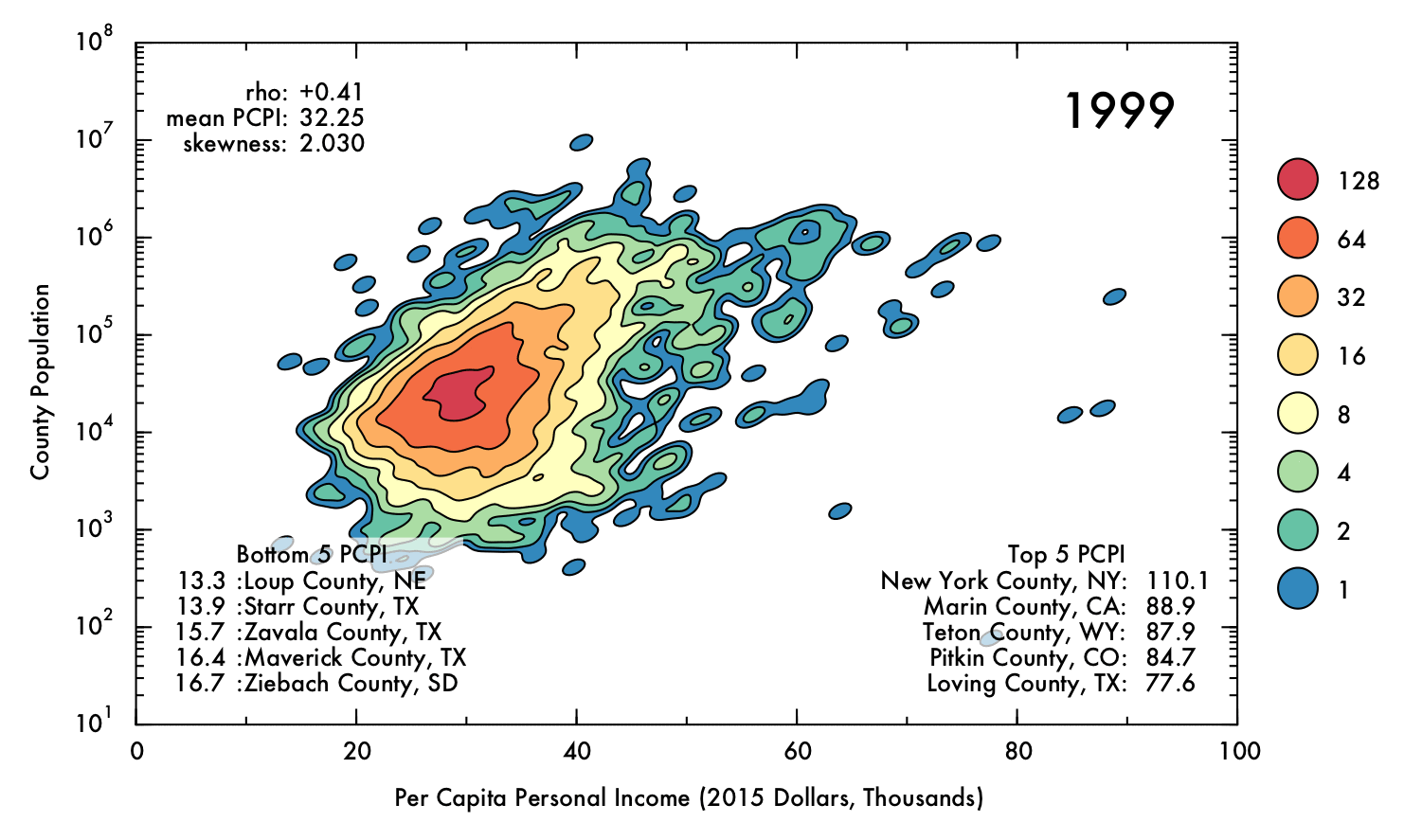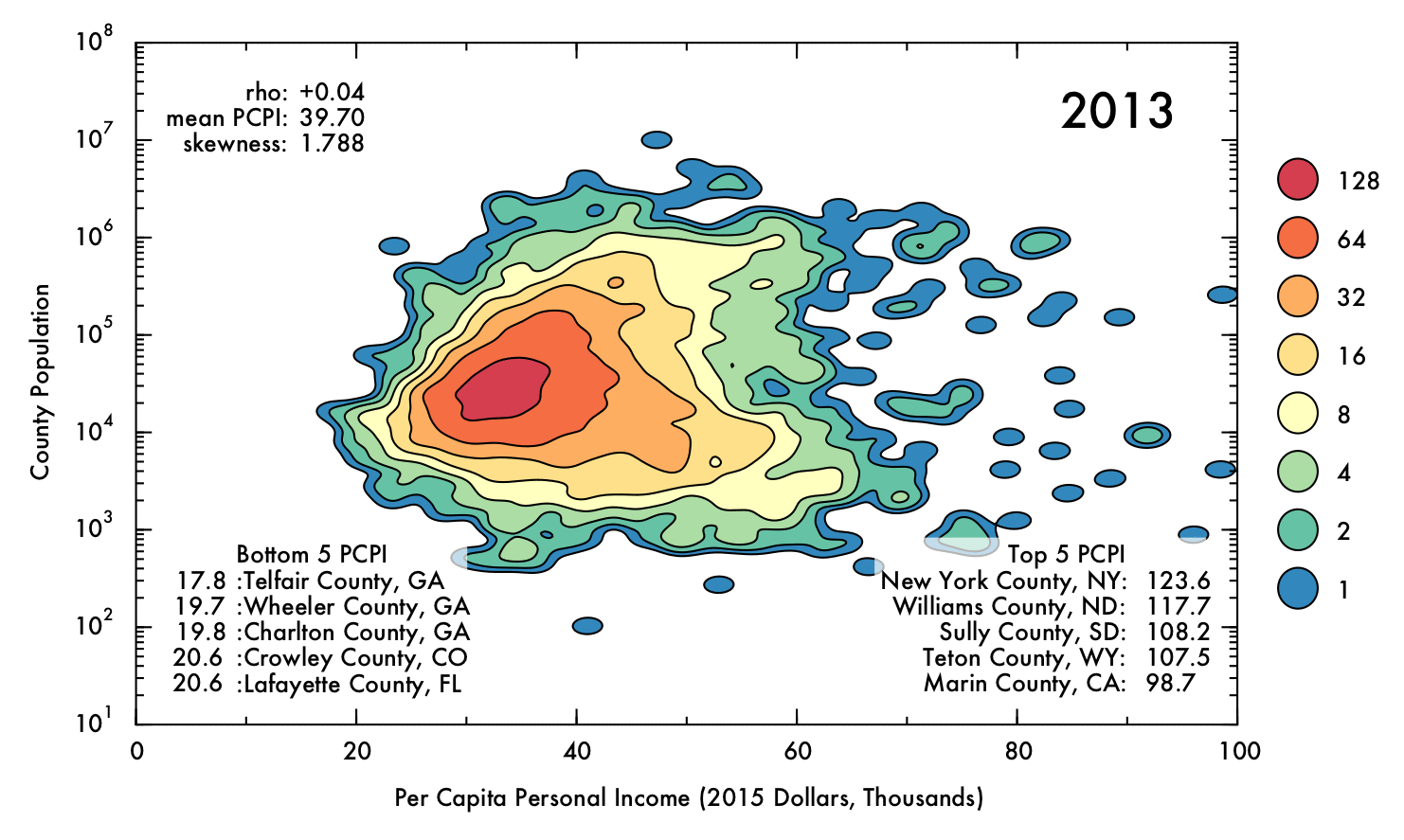
This report describes some exploratory analysis and visualization of county-scale data from the Federal Reserve Economic Database (FRED). I demonstrate that mean inflation-adjusted income has increased since 1970, though the inequality between high- and low-earning counties has also increased.